Project information
- Category: Neural Network, Multi-class Classification
- Source Data: Download
Project Details
Description
Iris flower classification is a popular dataset in machine learning projects. The dataset contains three classes of flowers: Versicolor, Virginica, Setosa and each class has 4 features like “Sepal length”, “Sepal width”, “Petal length” and “ Petal width”. The goal of the iris flower classification is to train the SVM mode and predict flowers based on their features.

As the dataset has labeled the variable, it is supervised machine learning. Supervised machine learning a is type of machine learning that are trained on well-labeled training data. Labeled data means that training data is already tagged with correct output.
In this project, I will solve the problem using neural networks: artificial neural networks (ANNs) as it is a supervised algorithm which rely on training data to learn and improve their accuracy over time. Once these learning algorithms are fine-tuned for accuracy, they are powerful tools in classification and clustering data.
How artificial neural networks work?
It is comprised of a node layers, containing an input layer, one or more hidden layers, and an output layer. Each node, or artificial neuron, connects to another and has an associated weight and threshold. If the output of any individual node is above the specified threshold value, that node is activated, sending data to the next layer of the network. Otherwise, no data is passed along to the next layer of the network.
Python Packages:
Roadmap:
Step 1:
Import packages:
import numpy as np import pandas as pd from sklearn.metrics import accuracy_score from sklearn.metrics import classification_report from sklearn.preprocessing import LabelEncoder from sklearn.model_selection import train_test_split from keras.utils.np_utils import to_categorical from keras.models import Sequential from keras.layers import Dense
csv_url = 'url' columns = ['Sepal length', 'Sepal width', 'Petal length', 'Petal width', 'Class_labels'] # Load the data df = pd.read_csv(csv_url, names=columns) # display first 5 rows data print(df.head())
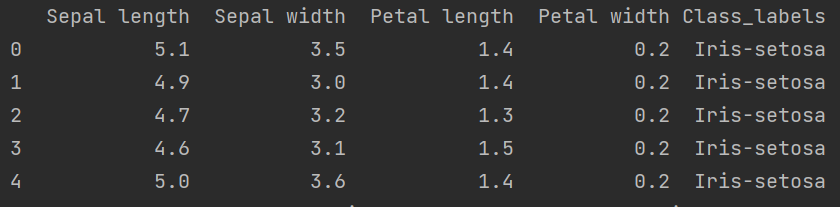
# Separate features and target data = df.values X = data[:,0:4].astype(float) Y = data[:,4]
Step2: Split a dataset into training and testing datasets
l_encode = LabelEncoder() l_encode.fit(Y) Y = l_encode.transform(Y) Y = to_categorical(Y)
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.2)
Step3: Train the model
in_dim = len(data[0])-1
model = Sequential()
model.add(Dense(8, input_dim = in_dim, activation = 'relu'))
model.add(Dense(10, activation = 'relu'))
model.add(Dense(10, activation = 'relu'))
model.add(Dense(10, activation = 'relu'))
model.add(Dense(3, activation = 'softmax'))
model.compile(loss = 'categorical_crossentropy', optimizer = 'adam', metrics = ['accuracy'])
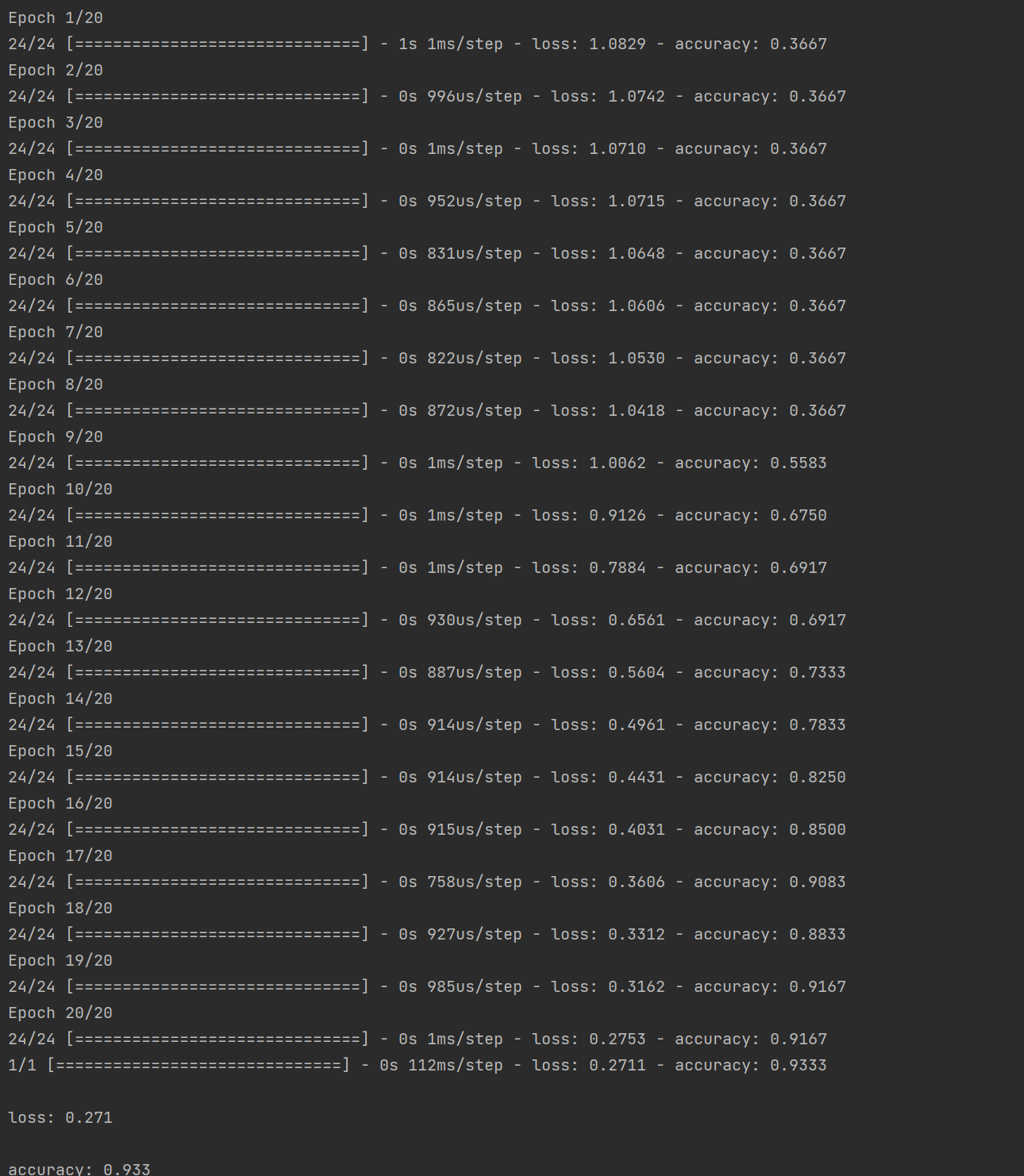
model.fit(train_x, train_y, epochs = 20, batch_size = 5)
scores = model.evaluate(test_x, test_y)
for i, m in enumerate(model.metrics_names):
print("\n%s: %.3f"% (m, scores[i]))
Step 4: Model Evaluation
pred = model.predict(test_x)
pred_= np.argmax(pred, axis = 1)
pred_ = l_encode.inverse_transform(pred_)
true_y = l_encode.inverse_transform(np.argmax(to_categorical(test_y), axis = 1)[:,1])
for i,j in zip(pred_, true_y):
print("Predicted: {}, True: {}".format(i, j))
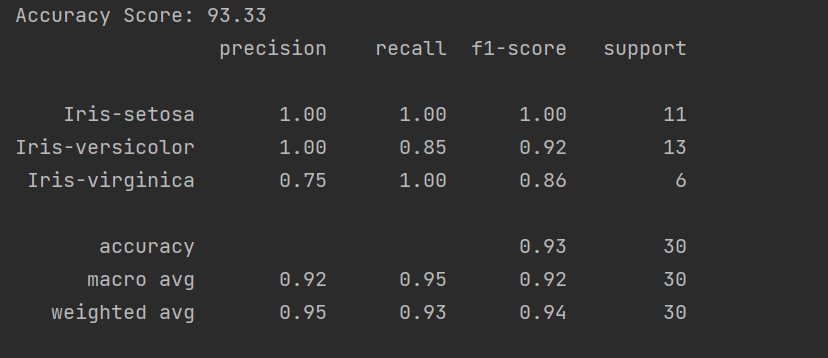
print("Accuracy Score:" ,"%.2f" % (accuracy_score(true_y, pred_)*100))
print(classification_report(true_y, pred_))
Step 5: Testing the model
#Testing
X_new = np.array([[3, 2, 1, 0.2], [4.9, 2.2, 3.8, 1.1], [5.3, 2.5, 4.6, 1.9]]).astype(float)
pred_new = model.predict(X_new)
pred_new_= np.argmax(pred_new, axis = 1)
pred_new_ = l_encode.inverse_transform(pred_new_)
print("Prediction of Species: {}".format(pred_new_))
