Project information
- Category: Logistic Regression Model, Classification
- Source Data: Download
Project Details
Description
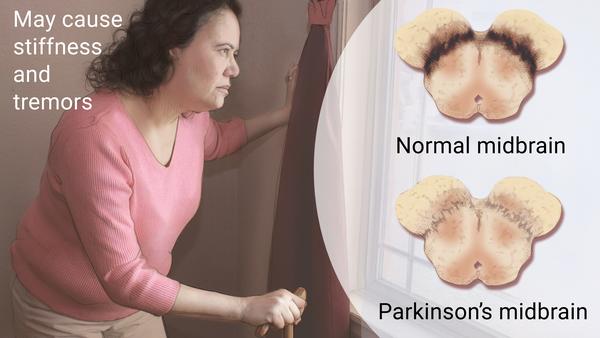
Parkinson's disease is a brain disorder that causes unintended or uncontrollable movements, such as shaking, stiffness, and difficulty with balance and coordination. Symptoms usually begin gradually and worsen over time. As the disease progresses, people may have difficulty walking and talking. The dataset contains two classes of status: 1 meaning yes and 0 meaning no and each class has 24 features.
Data Description:
The goal of the Parkinson’s disease is to train the random forest model, analyze importance of variables, tuning the accuracy of model, predict status based on their features.
As the dataset have labeled the variable, it is supervised machine learning. Supervised machine learning are types of machine learning that are trained on well-labeled training data. Labeled data means that training data is already tagged with correct output.
In this project, I will solve the problem using the algorithm: logistic regression as it is a supervised machine learning algorithm which analyzes data for classification. Also, logistic regression is one of the most robust classification methods.
Based on the tasks performed and the nature of the output, you can classify machine learning models into three types:
Types of Logistic Regression:
Methodology
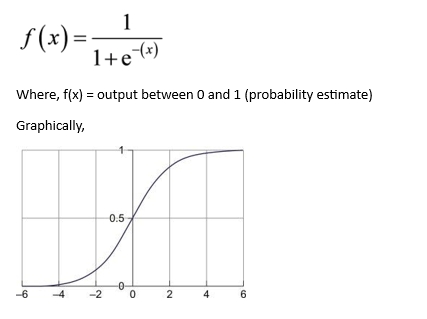
Logistic regression is a linear classifier, so you’ll use a linear function 𝑓(𝐱) = 𝑏₀ + 𝑏₁𝑥₁ + ⋯ + 𝑏ᵣ𝑥ᵣ, also called the logit. The variables 𝑏₀, 𝑏₁, …, 𝑏ᵣ are the estimators of the regression coefficients, which are also called the predicted weights or just coefficients.
The logistic regression function 𝑝(𝐱) is the sigmoid function of 𝑓(𝐱): 𝑝(𝐱) = 1 / (1 + exp(−𝑓(𝐱)). As such, it’s often close to either 0 or 1. The function 𝑝(𝐱) is often interpreted as the predicted probability that the output for a given 𝐱 is equal to 1. Therefore, 1 − 𝑝(𝑥) is the probability that the output is 0.
Python Packages:
Roadmap:
Step 1:
Import packages:
#import libaries import pandas as pd import seaborn as sns import numpy as np import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score from sklearn.metrics import classification_report from sklearn.linear_model import LogisticRegression
#Read the data url=r'url' df=pd.read_csv(url) print(df.head())
Step2: Analyze and visualize the dataset
# display base statistical analysis regarding the data print(df.describe())


# Separate features and target X=df.loc[:,df.columns!='status'].values[:,1:] Y=df.loc[:,'status'].values feature=df.drop(['name','status'], axis=1) feature_list=list(feature.columns) Y = data[:,4]
Step3: Split a dataset into training and testing datasets
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.20, random_state=42)
Step4: Train the model
LR=LogisticRegression(solver='liblinear', max_iter=3000, C=10, random_state=0) LR.fit(X_train,y_train)
- solver is a string ('liblinear' by default) that decides what solver to use for fitting the model. Other options are 'newton-cg', 'lbfgs', 'sag', and 'saga'.
- max_iter is an integer (100 by default) that defines the maximum number of iterations by the solver during model fitting.
- C is a positive floating-point number (1.0 by default) that defines the relative strength of regularization. Smaller values indicate stronger regularization.
- random_state is an integer, an instance of numpy.RandomState, or None (default) that defines what pseudo-random number generator to use.
Step 5: Model Evaluation
pred=LR.predict(X_test)
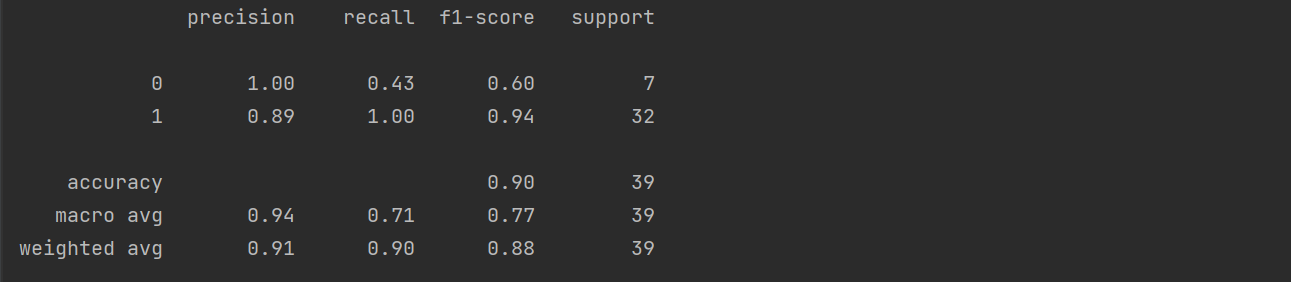
print('First Run Performance:'+str(accuracy_score(y_test,pred)*100))

print(classification_report(y_test, pred))
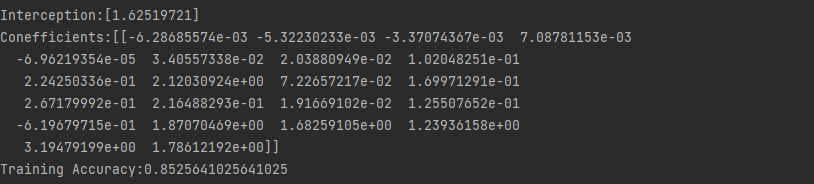
print("Interception:"+str(LR.intercept_))
print("Conefficients:"+str(LR.coef_))
print("Training Accuracy:"+str(LR.score(X_train,y_train)))
Step 6: Testing the Model
#Testing the model
X_new = np.array([[180.19800,201.24900,175.45600,0.00284,0.00002,0.00153,0.00166,0.00459,0.01444,0.13100,0.00726,0.00885,0.01190,0.02177,0.00231,26.73800,0.403884,0.766209,-6.452058,0.212294,2.269398,0.141929],
[241.40400,248.83400,232.48300,0.00281,0.00001,0.00157,0.00173,0.00470,0.01760,0.15400,0.01006,0.01038,0.01251,0.03017,0.00675,23.14500,0.457702,0.634267,-6.793547,0.158266,2.256699,0.117399],
[242.85200,255.03400,227.91100,0.00225,0.000009,0.00117,0.00139,0.00350,0.01494,0.13400,0.00847,0.00879,0.01014,0.02542,0.00476,25.03200,0.431285,0.638928,-6.995820,0.102083,2.365800,0.102706]])
pred_new = LR.predict(X_new)
# expected results:1,0,0
print("Prediction of Parkinson's Status : {}".format(pred_new))
